The patch will set the upload shaper to 90% of the achieved rate by default. I have not removed achieved_rate_adjust_down_bufferbloat from the equation.
1 Like
Thanks for the clarification.
Actually, I would appreciate if, instead of applying the patch literally, you implement both the old and the new way to calculate the new shaper rate, and DEBUG both, while actually applying the rate that my patch says to apply.
If you redo the patch, make sure the pass the direction into get_next_shaper_rate() and only apply these changes for ingress, as for egress these will actually do the wrong thing...
Thanks for the reminder. Out of curiosity, if I redo the patch, I will log both the right thing and the wrong thing anyway. But let me see what might be the result of the wrong way.
By default, we have:
achieved_rate_adjust_down_bufferbloat=0.9
shaper_rate_adjust_down_bufferbloat=0.9
Let's assume that achieved_rate_adjust_down_bufferbloat <= shaper_rate_adjust_down_bufferbloat, which is true both by default and in the configuration that sets shaper_rate_adjust_down_bufferbloat to 1 while leaving achieved_rate_adjust_down_bufferbloat at the lower value.
Let's denote achieved_rate_adjust_down_bufferbloat as C and shaper_rate_adjust_down_bufferbloat as D >= C.
On egress, the achieved rate is logically below the shaper rate, but, due to laggy measurements (and only for this reason), on paper, this is not guaranteed. Anyway, after any adjustment of the shaper rate, the script enters a refractory period, and during a refractory period, the shaper is not adjusted. So it is still relatively safe to assume, as a first approximation, that the lag does not apply, and achieved_rate_kbps < shaper_rate_kbps.
The old way is (back to floating point in pseudo-C):
adjusted_achieved_rate_kbps = achieved_rate_kbps * C;
adjusted_shaper_rate_kbps= shaper_rate_kbps * D;
shaper_rate_kbps= (adjusted_achieved_rate_kbps > min_shaper_rate_kbps &&
adjusted_achieved_rate_kbps < adjusted_shaper_rate_kbps ) ?
adjusted_achieved_rate_kbps : adjusted_shaper_rate_kbps;
Let's simplify. We know that achieved_rate_kbps < shaper_rate_kbps and C <= D. Therefore, adjusted_achieved_rate_kbps < adjusted_shaper_rate_kbps. Therefore, the second part of the condition is always true on egress. So, effectively, in the right way we have:
adjusted_achieved_rate_kbps = achieved_rate_kbps * C;
shaper_rate_kbps= (adjusted_achieved_rate_kbps > min_shaper_rate_kbps) ?
adjusted_achieved_rate_kbps : (shaper_rate_kbps * D);
Now the wrong way:
adjusted_achieved_rate_kbps = achieved_rate_kbps * C; /* same as in the right way */
shaper_rate_kbps = (adjusted_achieved_rate_kbps > min_shaper_rate_kbps) ?
adjusted_achieved_rate_kbps : shaper_rate_kbps;
So effectively, the difference is that, if adjusted_achieved_rate_kbps < min_shaper_rate_kbps (e.g., if the upload is idle), in the right way, the egress shaper decays according to D, and in the wrong way, it doesn't. For non-idle upload (and thus for Discord), there is no difference. If D = 1, there is no difference at all.
Not exactly, achieved_rate <= shaper_rate (if measured at shaper_egress, otherwise even achieved_rate > shaper_rate is possible). Also it is not only "laggy measurements" but the fact that we aggregate over epochs meaning any achieved_rate measurement can contain 2 shaper settings and resulting traffic rates. That in turn means that even for measurements at the shaper egress essentially achieved_rate <=> shaper_rate... as I keep repeating the achieved_rates are not precise and it is IMHO best to treat them as just that estimates with inherent uncertainty...
This is a bit of wishful thinking, let's model this cow as a sphere of 1m radius on a frictionless plane...
Anyway, I think I accept your request for a new policy option "trust ingress achieved_rates unconditionally" (I for one can safely leave that option disabled and ignore it, more adventurous minds or those on marginal links can do differently...), but let's do that correctly and not hack and slash with unexplained terms like right and wrong (seen as a policy issue there is no right or wrong).
I had no time to work on this. Therefore, today's test is just a retest with exactly the same parameters as yesterday, except that there were more people in the Discord call, and the latency target has been reduced:
dl_delay_thr_ms=100 # (milliseconds)
ul_delay_thr_ms=100 # (milliseconds)
Perhaps this is too aggressive for my LTE connection.
Unfortunately the "unusually good state of the LTE link" objection to the yesterday's results cannot be dealt with. Here is the speedtest result without SQM, which is, on paper, better than yesterday, but de-facto, during the call, it was worse:
Waveform bufferbloat test got an F, as expected.
The meeting nevertheless was not 100% successful, because the link by itself was not good enough. Subjectively, the call went much worse than yesterday, but still not bad enough to turn the script off. There were 9 people, out of them 4 with video. There were periods of extreme stuttering, so I missed some parts of the conversation (e.g. "we need to ask the cust... omer... which... <missed some words> they want"), but Discord has recovered by itself after all such stuttering periods - which is the important point here. There were also some periods when Discords showed a "RTC Disconnected" red message, while still delivering some voice and video with stuttering. There are also quite lengthy periods where the incoming bandwidth is significantly higher than 100% of the shaper rate, thus confirming the theory.
Perhaps the same logic of trusting the incoming rate as a known lower bound of the bottleneck bandwidth has to be extended to a no-bufferbloat case as well - but I do get the concerns about the control loop stability for the case when the control loop does work (for UDP media streams, the whole point is that it usually doesn't).
Results have been uploaded to pCloud.
Not really, what you essentially implemented is not so much "trust the achieved rate" but more a "dynamic minimal rate where the controller disengages". As long as the achieved rate stays the same the shaper rare will never decline to the minimal rate (as long as achieved_rate * factor > minimal_rate) hence "dynamic". Or put differently, I prefer "trust, but verify" which in essence is what min(achieved_ratefactor, shaper_ratefactor) gives us... but I think with bursty macs like DOCSIS, DSL (with G.INP*), and WiFi achieved rate simply can vary a lot, and once we start low pass filtering the achieved rate to deal with that artificial variability, we lost temporal fidelity of responding to bufferbloat...
My take on this is more, if you used an actually meaningful minimal rate and delay thresholds that change should not be necessary.... and you would actually be able to easily predict controller behaviour.
Here my interpretation of the "stuck on minimalrate" phenomenon is that this happens, because even at that rate the evoked delay stays above threshold and actively inhibits the controller from increasing the rate again. Is that intepretation correct or is something else happening as well?
) With G.INP upstream and modem exchange data transfer units (DTUs) and use an ACK scheme in which the receiver tells the sender which DTUs to retransmit. E.g. on downloads the modem tells the DSLAM which DTU(s) where receives incorrectly, the modem will hold all DTUs with higher "sequence numbers" in its buffers to avoid introducing packet re-ordering while requesting retransmission of the defect DTU) the DSLAM will now (iteratively) retransmit that DTU until the modem signals successful reception or until that DTU has aged out of the DSLAMs buffers. The modem will now disassemble all DTUs into packets in the same order they arrived at the DSLAM (with potentially missing packets if retransmission was not successful) and it will essentially release these packets at line rate. In a case with a bridged modem on a 1 Gbps link to a router, that burst arrives at 1 Gbps, assuming for a second that burst fits completely into our rate sampling window, we would see an achieved rate of 1 Gbps even if say the DSL link is only 250 Mbps or even just 100Mbps (and even if it does not fully align with a sampling period having such bursts in the byte accumulation is not helping with getting useful data). Following your proposal we might end up setting the shaper to 10000.9 = 900 Mbps, hardly ideal for a 100 link sure after the refractory period the achieved rate will be lower and we will drop from 900 to say 50 Mbps, but such extreme drops cause problems of their own...
So "trust the achieved rate" clearly can not mean take it ay face value... at the very least it needs to be compared to the maximum defined rate for our controller and potentially clamped to that value if larger (or some smoothing would need to happen)...
To repeat myself achieved rates are not directly actionable estimators of the bottleneck rate and I consider it risky to treat them as such.
Something else is happening as well. Namely, throttling the shaper does not help the sender to slow down, or does not help quickly enough, because it is a UDP media stream (so ACKs do not exist), and switching to a different quality/resolution is not always implemented or is slow. In other words, due to the lack of effective sender feedback, the shaper rate is completely ineffective as a bufferbloat control for ingress.
1 Like
Talk to you application supplier, that is not standards conforming behavior for traffic over the internet...
That is a red herring, sorry. UDP applications need to implement their own timely feed-back channel to adjust sending rates to network conditions. Sure TCP does that as part of the protocol, but the moment an application goes UDP the onus to do proper congestion control falls into the hands of the application developer (that said QUIC is UDP based and still implements congestion control of some sort).
Again and very respectfully, such applications need to be dropped like hot potatos, they are either standards conform nor safe to use over the existing internet.
If your model of a 1.1 Mbps stream over a 1 Mbps bottleneck is true then you simply continue to DOS your self, not much that autorate can do there.
With that of my chest, back to more productive discussion, are there any in application toggles to lower the video quality/bandwidth demands? Either on your side or in the configurarion of the service (cloud, your companies servers)?
Not sure. Since I used to use WireGuard for everything - hence UDP, and an appropriate shaper rate made enormous difference.
Hey! I think this has been a productive and interesting conversation.
That's because the feedback mechanism still exists for the TCP streams that are encapsulated inside your WireGuard tunnel. Look, the shaper drops WireGuard packets. After decryption, some TCP packets end up therefore missing and not ACKed. The sender therefore slows down.
For Google Meet (used at the previous job), yes. I could even turn the video off completely. For Discord, apparently no - but it does appear to reduce the video quality after some time.
Jitsi Meet appears to reasonably auto-tune the bandwidth used when the other party uses Chrome but not Firefox.
Anyway we have so many disagreements about the policy that I think that the best move for me would be to unsubscribe from this thread and just quietly use a modified version (or, eventually, a rewrite that I am working on) that does the unsafe things that happen to work on my (too-unusual and unsupportable) LTE connection.
One last P.S.: regarding the "stall-detection" feature that was added because of my connection - if you have no other way to test, and no other users, I would not object to the removal from the official version.
Me telling @patrakov what he knows already is not really helping to deal with his rotten LTE situation.... ![]() so I wanted to signal I am done ranting and back at trying to find ways of making things better.
so I wanted to signal I am done ranting and back at trying to find ways of making things better.
Because in the end, it helps nobody to note that the application he has to use is not really suited for his situation (and he will not be alone in that, I bet a number of developers simply assume X Mbps to be the lowest they ever need to deal with, and users on < X links are left out in the cold).
This is different, wireguard does not need to do congestion control, because all of the traffic it carries already need to do, if a wireguard packet is dropped the payload packets it carries are dropped as well and the respective unencrypted flows are expected to respond to that signal...
The same is true for UDP, the only difference is that this response to encountered congestion is not integrated part of the protocol stack, and hence applications can and do get this wrong... Using UDP is not "get out of the requirement to avoid congestion collapse" requirement for internet protocols/applications ![]()
Well, policy is something you set and if you are happy with I will shut up. My beef is with making proposals like "trusting the achieved rate" unconditionally when we have no empiric data supporting that and a lot of already known conditions when this is not going to work as desired, because empirically achieved_rate != instantaneous bottleneck_rate.
Well, if you do and it works, by all means let @Lynx know, unlike me he is quite open to explore new avenues and try things. (This being his project you can also simply ignore me ![]() )
)
For me this triggers when during low load conditions delay probes are lost, but honestly that probably mainly means that I have misconfigured the stall_rate so this triggers too often... so clearly my fault the biggest issue with that feature is mostly that it revealed issues in our conceptual concurrency handling, but these are fixed in 2.0 as far as I can tell from the outside. Removing this feature (which can essentially already been disabled seems not a good idea (in spite of my earlier ranting) compared to making sure this actually works as described ![]()
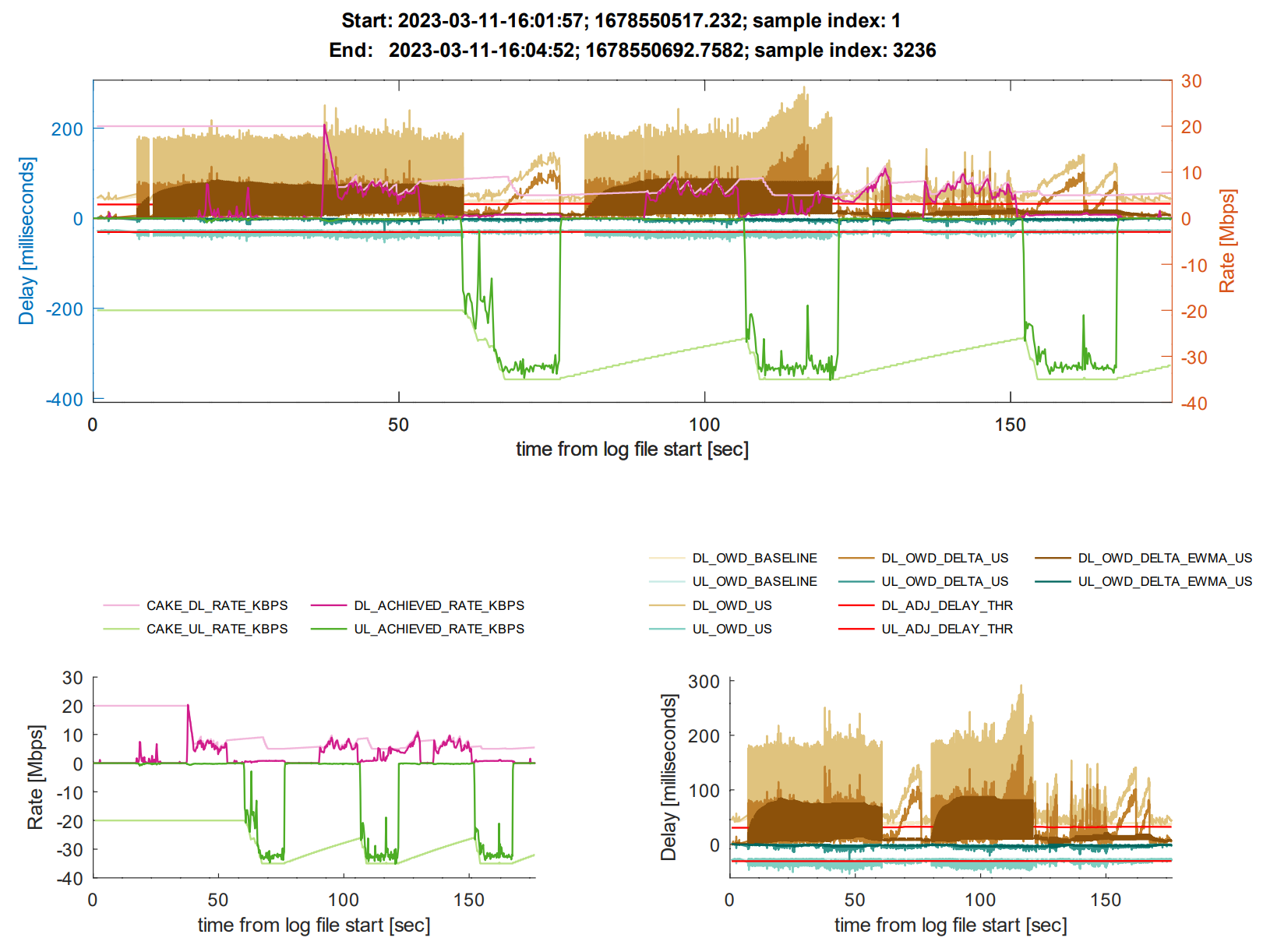
More experiments with @Lochnair's new and updated tsping binary, as follows.
Timecourse:
Raw CDFs:

This is using:
reflectors=(
94.140.14.15 94.140.14.140 94.140.14.141 94.140.15.15 94.140.15.16 # AdGuard
64.6.64.6 64.6.65.6 156.154.70.1 156.154.70.2 156.154.70.3 156.154.70.4 156.154.70.5 156.154.71.1 156.154.71.2 156.154.71.3 156.154.71.4
208.67.222.222 208.67.220.2 208.67.220.123 208.67.220.220 208.67.222.2 208.67.222.123 # OpenDns
185.228.168.168 185.228.168.9 185.228.168.10 185.228.169.11 185.228.169.9 185.228.169.168 # CleanBrowsing
149.112.112.112 9.9.9.10 9.9.9.11 149.112.112.10 149.112.112.11 # Quad9
)
Funny, in the upload OWDs we see the steps from ICMP timestamp resolution being one 1 millisecond.
I wonder why our reflector recycling code did not (yet?) replace the reflectors with > 200ms RTT?
Would be interesting to see a bidirectional load test.
Do you have flent/netperf installed somewhere?
Also, during the upload tests, the upload OWD seems to stay flat, but the download OWDs increases ever upward, that looks suspicious.
Exactly what I was wondering. Let me look at the log manually.
REFLECTOR; 2023-03-11-16:02:57; 1678550577.155771; 1678550577.154974; 185.228.169.168; 36160; 114028; 77868; 10000; 7529; 68089; 60560; 10000; 26006; 38005; 11999; 10000; 1100; 1593; 493; 10000
DEBUG; 2023-03-11-16:02:57; 1678550577.158613; Warning: reflector: 185.228.169.168 dl_owd_baseline_us exceeds the minimum by set threshold.
DEBUG; 2023-03-11-16:02:57; 1678550577.160692; Starting: replace_pinger_reflector with PID: 5064
DEBUG; 2023-03-11-16:02:57; 1678550577.166323; replacing reflector: 185.228.169.168 with 208.67.222.2.
185.228.169.168 was kicked.
REFLECTOR; 2023-03-11-16:03:57; 1678550637.363465; 1678550637.361214; 185.228.169.11; 39200; 113017; 73817; 10000; 10329; 81440; 71111; 10000; 26166; 38204; 12038; 10000; 2567; 2905; 338; 10000
DEBUG; 2023-03-11-16:03:57; 1678550637.366672; Warning: reflector: 185.228.169.11 dl_owd_baseline_us exceeds the minimum by set threshold.
DEBUG; 2023-03-11-16:03:57; 1678550637.371758; Starting: replace_pinger_reflector with PID: 5064
DATA; 2023-03-11-16:03:57; 1678550637.379783; 1678550637.379100; 4487; 29908; 89; 85; 1678550637.3622590; 149.112.112.11; 134; 40476; 84000; 10329; 43524; 32400; 26170; 31000; 2706; 4830; 30342; 6; 0; dl_high_bb; ul_high; 5000; 35000
DEBUG; 2023-03-11-16:03:57; 1678550637.381509; replacing reflector: 185.228.169.11 with 156.154.70.4.
And so was 185.228.169.11.
So the replacement code works, right?
But yes the plots reveal something a bit dodgy. Any idea what's going on?
@moeller0 ah maybe @Lochnair changed the columns in this new tsping version?
while read -r -u "${pinger_fds[pinger]}" timestamp reflector seq _ _ _ _ dl_owd_ms ul_owd_ms _
root@OpenWrt-1:~/cake-autorate# tsping -D -m 9.9.9.9
Starting tsping 0.2.3 - pinging 1 targets
1678552468.211457,9.9.9.9,0,59668164,59668182,59668182,59668211,47,29,18
1678552468.310463,9.9.9.9,1,59668265,59668282,59668282,59668310,45,28,17
1678552468.410431,9.9.9.9,2,59668365,59668382,59668382,59668410,45,28,17
1678552468.518550,9.9.9.9,3,59668465,59668481,59668481,59668518,53,37,16
1678552468.620138,9.9.9.9,4,59668565,59668587,59668587,59668620,55,33,22
1678552468.745638,9.9.9.9,5,59668666,59668711,59668711,59668745,79,34,45
1678552468.835267,9.9.9.9,6,59668766,59668802,59668802,59668835,69,33,36
1678552468.918931,9.9.9.9,7,59668866,59668890,59668890,59668918,52,28,24
^C
No that seems OK, right? I don't understand what the very last column: 'Finished' relates to.
Here is a plot of the OWDs without those bad CleanBrowsing reflectors:

Just the OWDs:

@moeller0 is my max upload 35Mbit/s just way too low then?
printf(FMT_OUTPUT, ip, result.sequence, result.originateTime, result.receiveTime, result.transmitTime, result.finishedTime, rtt, down_time, up_time);
So the last is truly the upload/send direction and the next to last the download/receive direction... I guess I would have ordered them naturally first up the down, but this looks consistent.
But your extraction seems simply to be wrong:
timestamp reflector seq _ _ _ _ dl_owd_ms ul_owd_ms _
should be
timestamp reflector seq _ _ _ _ _ dl_owd_ms ul_owd_ms
1 Like
Was it changed? Or did I just mess that up from the start. Yikes!
1 Like
Finished is the timestamp from receiving the return packet sent from the remote side conataining the first 3 timestamps again, the final timestamps gets added once the process for that timestamp request is finished I would guess as rationale for the name , I prefer the following description:
TSPING: result.originateTime, result.receiveTime, result.transmitTime, result.finishedTime
LOGICAL: local_send, remote_receive, remote_send, local_receive.
No idea... I am still far away with my version to implement new ping_wrappers.