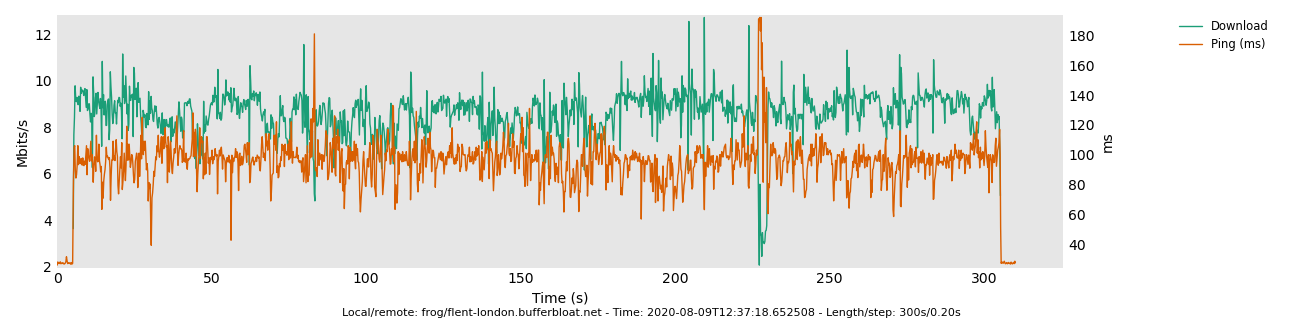
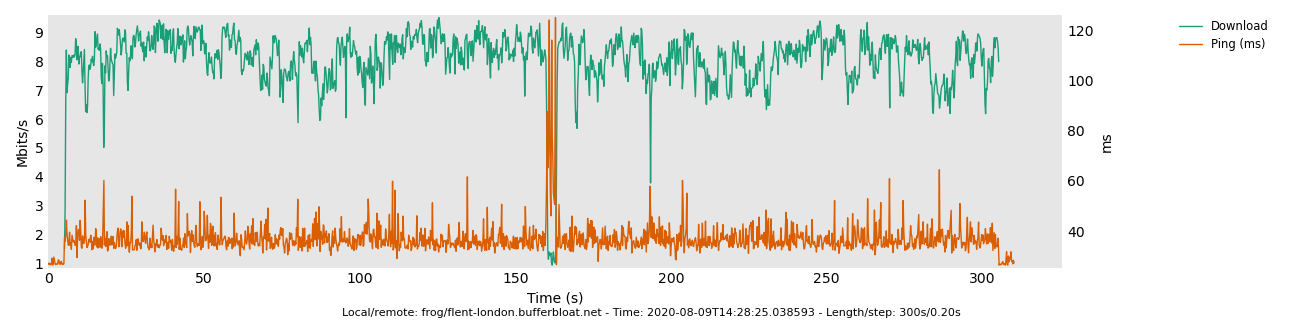
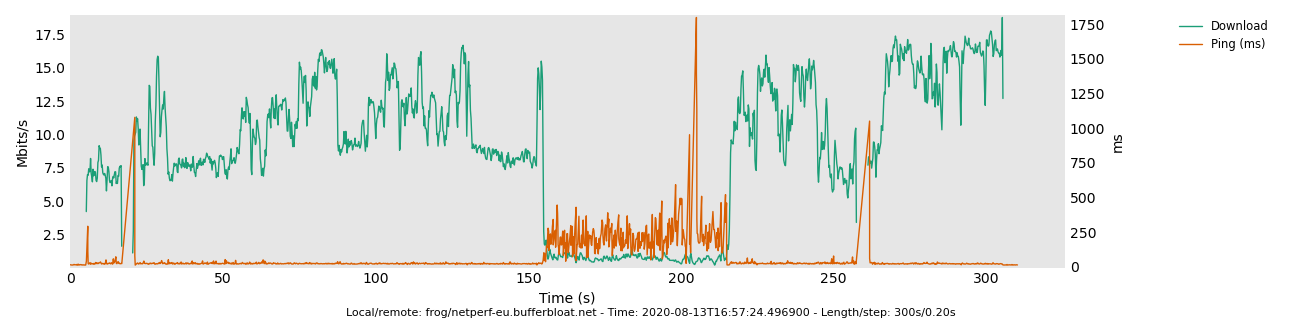
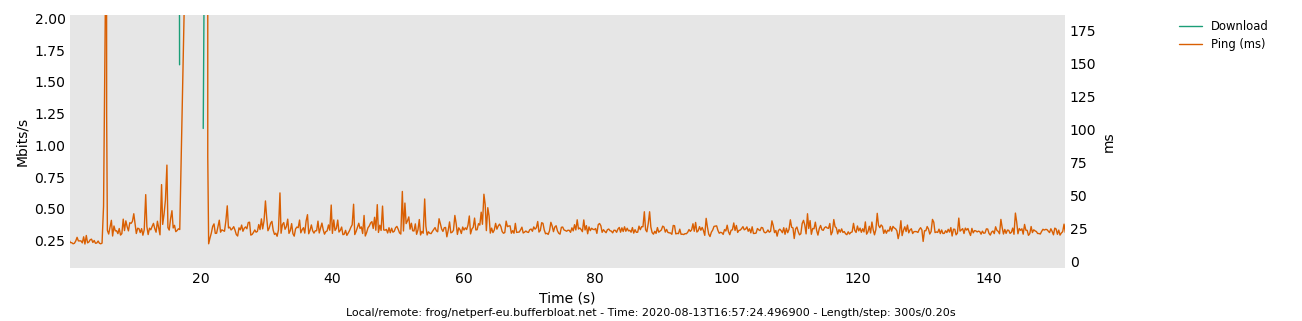
Partially because that test measures the wrong thing. ![]() That is because "rrul" testing the performance of 3 of 4 hardware queues which are filling up occupying airtime independently. A better comparison test for 5ms vs 10ms target is the rrul_be test, or the tcp_nup test I just mentioned above.
That is because "rrul" testing the performance of 3 of 4 hardware queues which are filling up occupying airtime independently. A better comparison test for 5ms vs 10ms target is the rrul_be test, or the tcp_nup test I just mentioned above.
This thread has got really long, and I so appreciate everyone leaping on it. Somewhere in the past part of this thread we talked about how using packets, rather than bytes, in the high and low watermarks was probably a source of weirdness. A way to test this is for someone to try the regular -ct code, not the smallbuffers version, on the lower target. @tohojo who has his fingers in too many pies and doesn't even have this chip seemed to have some insight on that.
elsewhere (not on this thread, I think) I talked about how unbounded retries were messing wifi up in the case of interference. The only way know how to look at this is with aircaps.
and over here I talked about how testing for only a minute bit me badly: http://blog.cerowrt.org/post/disabling_channel_scans/ so -l 300 on a given test, and taking a long walk might help...
so far, to me, the net sum of testing was that 10ms seemed a safe default for the -ct-smallbuffers version, and worse case we should try to push that into the next mainline release. Actually getting
something even better and more consistent than that would be great. I did just get a new
x86_64 box that I can start putting custom kernels on.