I wanted to add to this old thread because to me it's not very clear from the results posted that changing the AQL TX queue length does in fact have a significant effect on both latency and throughput, and that it might be worthwile to spend time on tuning this.
Below are some examples:
tx queue limit of 5000:
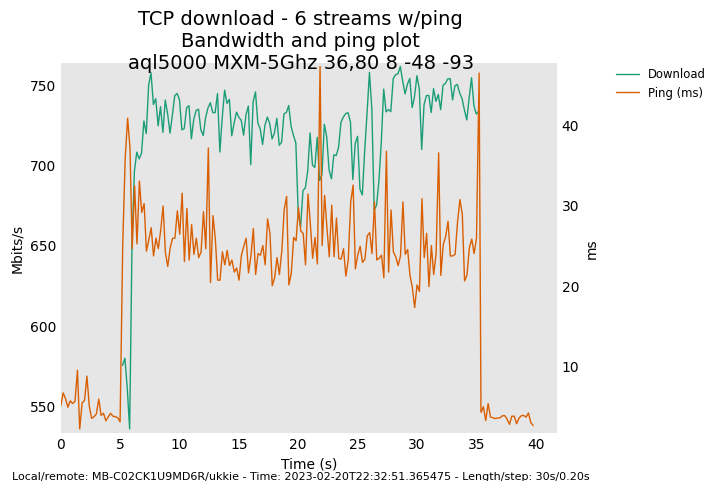
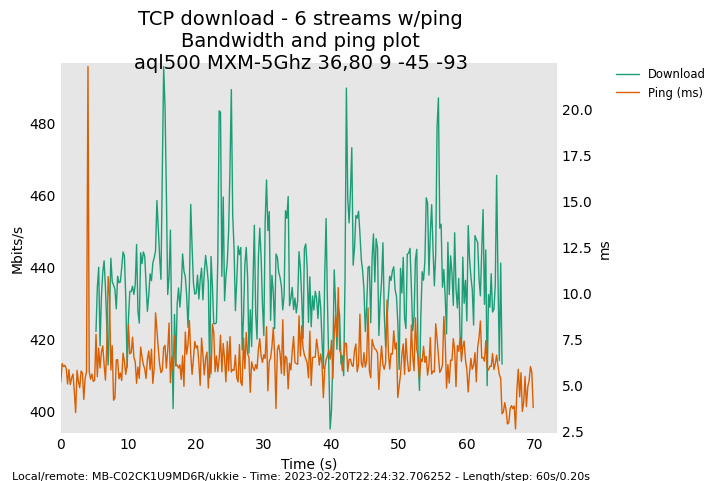
tx queue limit of 1500, this seems to be a good compromise between latency and throughput:

tx_queue_limit of 500, even lower latency but now throughput takes a big hit:
I didn't use rrul tests because I've found latency in the rrul test is basically meaningless on MacOS as there appears to be so much buffering going on on the Mac itself: if I test latency from another station when rrul is running the latency is much much lower than what flent reports. (Ideally we'd plot that in these rrul graphs!). But in general the result is: the lower the AQL length the bigger the down/up disparity and marginal improvements in latency.
For the record: These test were done on an R7800 running an NSS enabled snapshot build, with the "do_codel_right" patch set to 5ms target and 50ms interval, NAPI_POLL_WEIGHT and ATH10K_NAPI_BUDGET patched to 8, all of which seem to cause no adverse effects in a typical
household of 4 - in fact, it's great ![]()
A quick way to change the queue length yourself is:
for ac in 0 1 2 3; do echo $ac 1500 1500 > /sys/kernel/debug/ieee80211/phy0/aql_txq_limit; done