Yep that's another patch that slipped out somehow Sorry. Gonna check what happened there.
Edit: Well obviously missed the first patch adding the CONFIG_ARM_SBSA_WATCHDOG symbol, that should be fixed now. Shouldn't really be diffing patches at 1 AM. Curious if that fixes your issue.
@dtaht I just built and flashed 5.15 with the patch (which applied cleanly on top of 5.15.72), but all connectivity is gone. SFP+ died, 2,5G doesn't come up, the switch the router was attached to drops the link to 10 Mbps (on a Gbps link) but no ping there either.
I have no serial set up on this hardware, so I'm afraid you'll need someone else to find out what's going on here. Maybe @sumo can help out?
Hi @Borromini. This is extremely strange - the BQL change is totally unrelated to link handling whatsoever. 2x 10G SFP+ and 1G work the same way in my setup with and without this patch. Just to double-check is exactly the same baseline (just without the applied patch) behaving as expected?
@mwojtas Sorry for the noise, looks like a typical PEBKAC. Builds with the BQL patch boot just fine on both RB5009UGs I got. So looks like some late evening thing on my side. Thank you for the work.
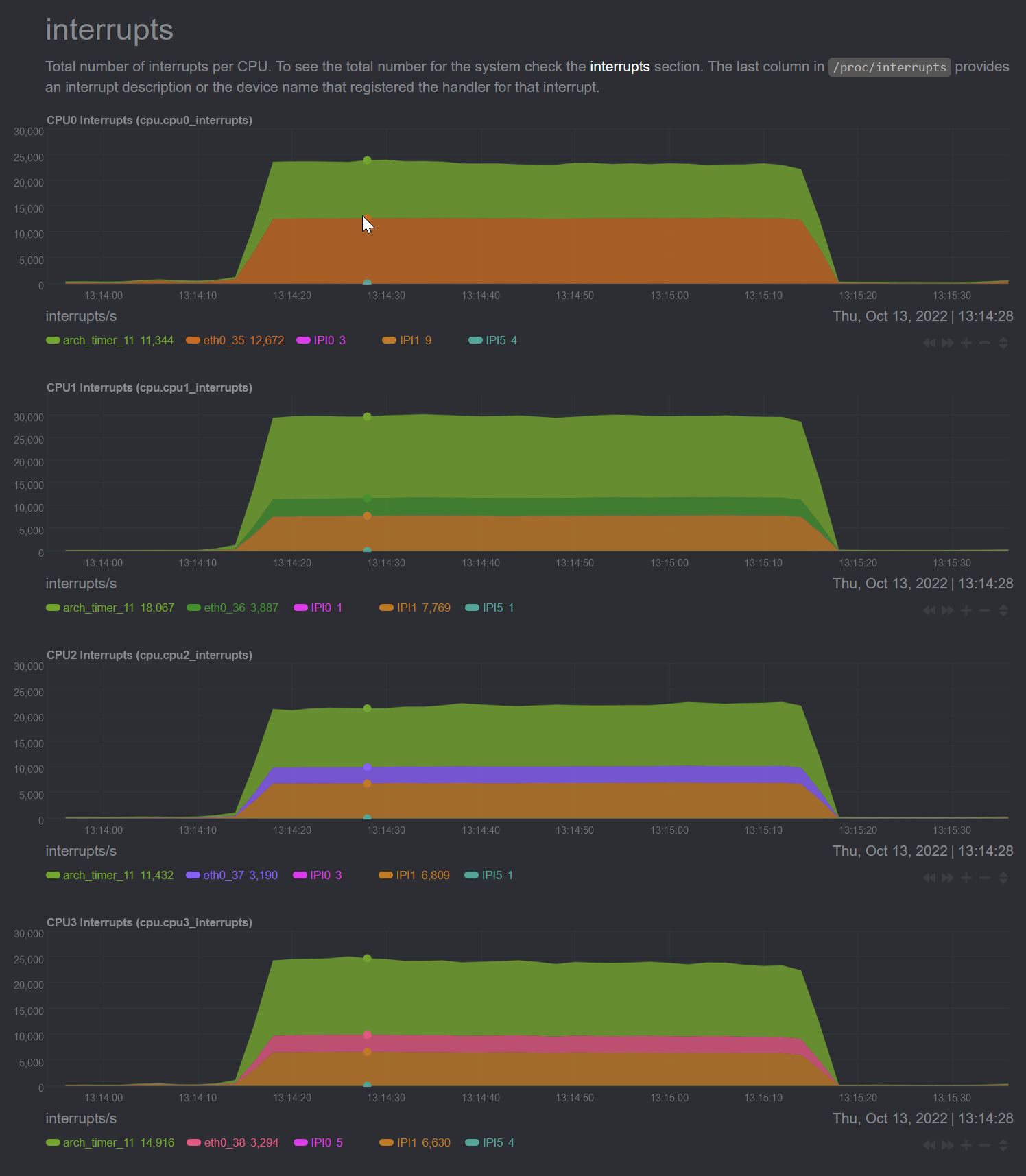
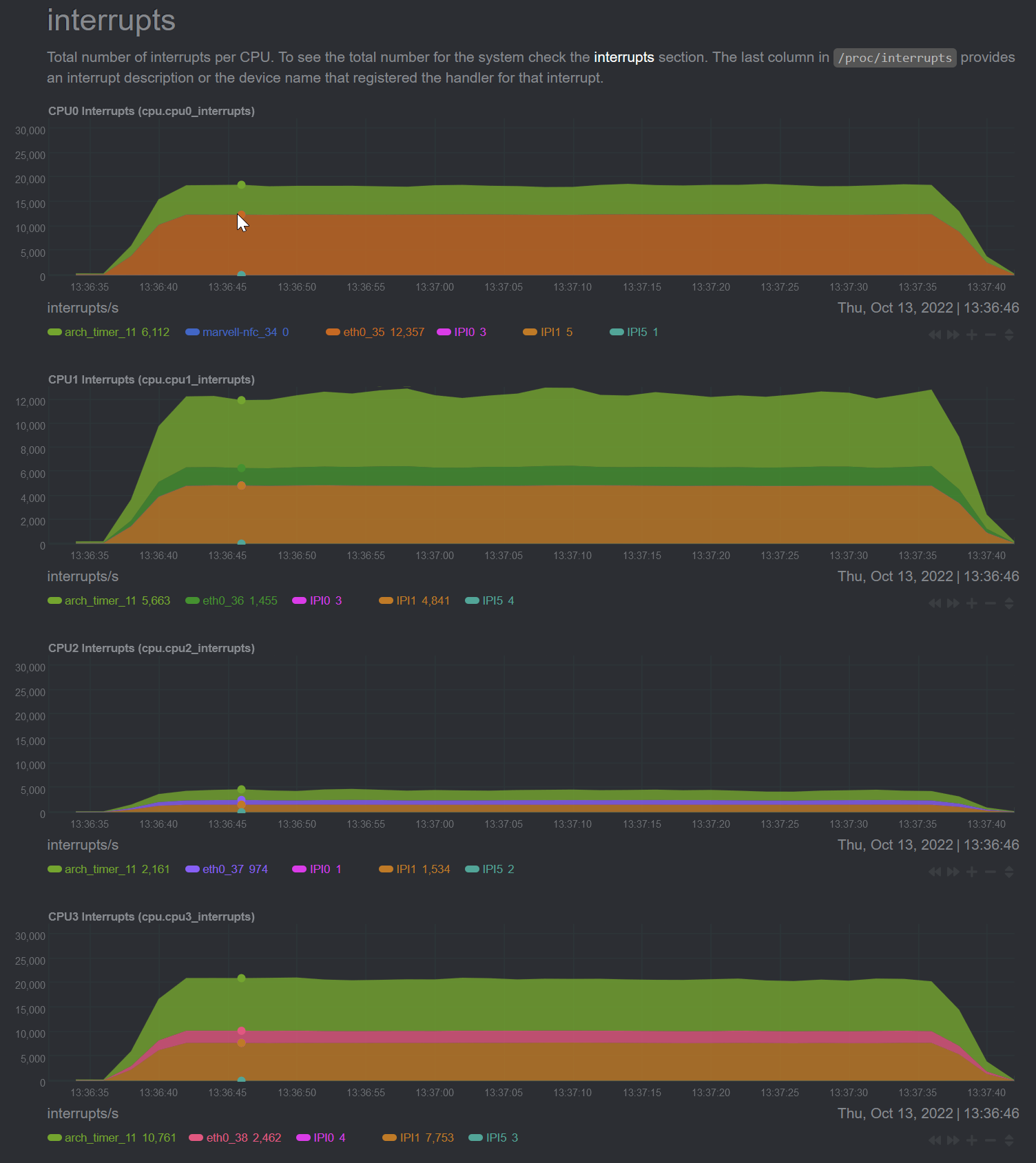
@dtaht I'm seeing counters now, i suppose eth0 is what I should be looking at here?
Even more useful, to me, would be to hit it hard with multiple iperf or flent flows and see at what level it stablizes at using:
fq_codel # which doesn't split GSO packets and will be 64-132k
cake gso-split # which does, but it's higher overhead
on the mq interace - also cake gso-split #
cake bandwidth someprettylargenumber # As high as it can go. I am hoping we can shape 2GBit per core on this arch
In all these cases it interacts with the BQL subsystem (which just chopped 1/10 or more of the latency and jitter out of this chipset. yay! HALF a ms down from 12!! from 8 lines of code! what more could you want? )
My goal (elsewhere on many threads) was to be able to observe and reduce interrupt latency to where things like BQL were running at below 32k at a gbit. I don't know what a right number would be at 10gbit or 2.5.
A related hope was to be able to reduce the coalescing interval, and also that by modifying NAPI_POLL_WEIGHT on arm architectures to 8 or less, we could start seeing major reductions in microseconds between rx and tx and get openwrt's networking closer to a fluid model,
and for all I know, speed things up due to using cache more efficiently.
I don't have any numbers for how fast the a72s can context switch, but the a53s could do it WAY faster than x86 could. The kinds of numbers we've inherited from the x86 world seem to be waay too large and too optimized for server, not routing workloads.
Another long deferred work was to make BQL multi-core, which would cut the amount of data outstanding on all the rings to just what is needed.
My (now slightly less) long term (formerly seemingly) crazy idea was to attempt to make this platform into a ISP fiber tower -> cake based shaper, leveraging either libreqos.io or (more likely) bracketqos, which leverages rust, xdp, and ebpf: BracketQos - Rust, EBPF, XDP, & cake, oh my!
I will check blqmon, looks like i'd need to package it for OpenWrt. That might take some time to get done, I'm a bit rusty in that department.
Any recommendations on how to set up flent/iperf testing? I suppose the RB5009UG should be sitting in the middle, right? I got a 2,5G capable desktop, but no 10G clients. Do have a switch that can do 10G though and I can run OpenWrt on. Not sure how well that will perform though as an endpoint?
It mostly sounds way over my head to me but I believe you when you say it's crazy .
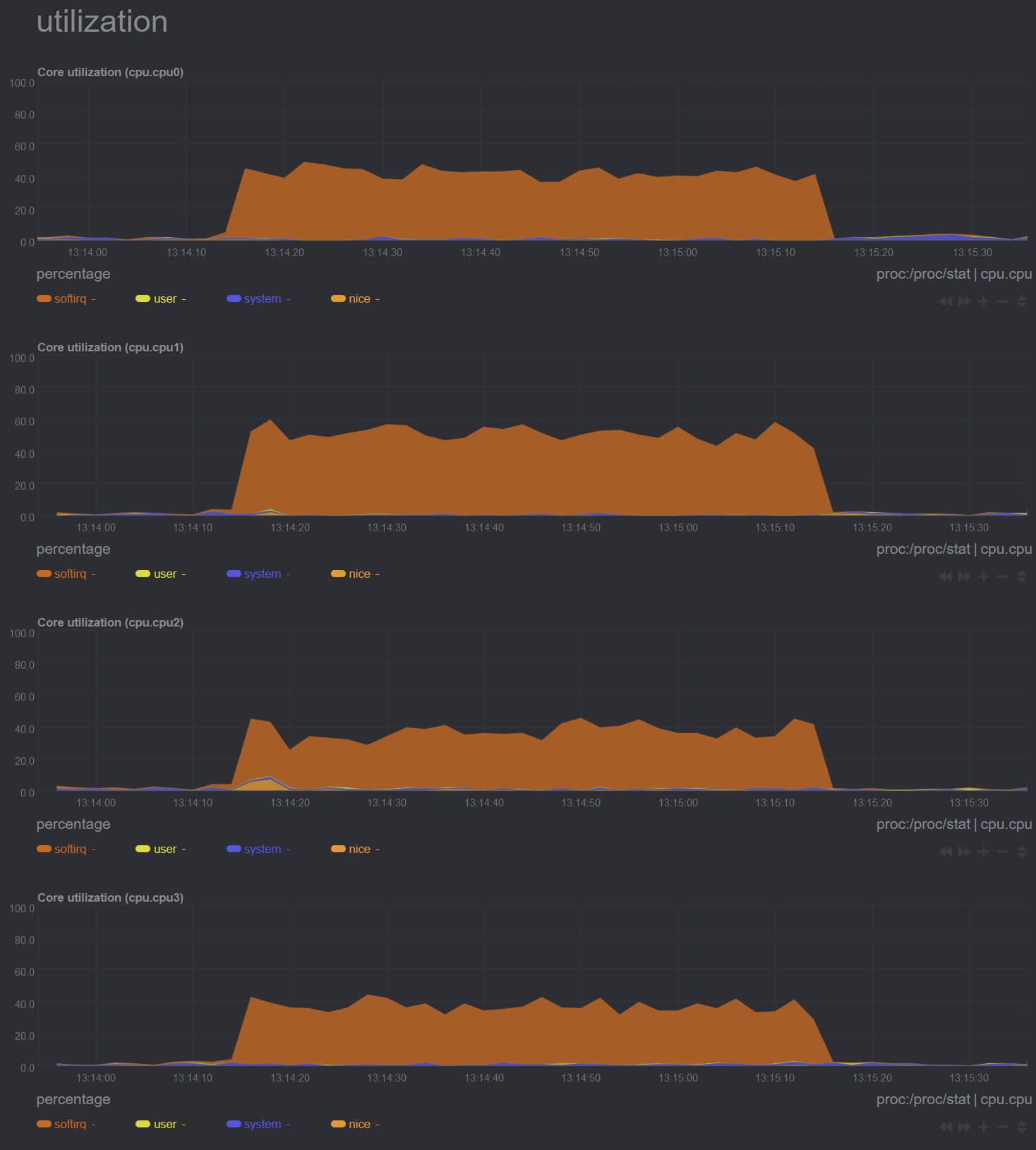
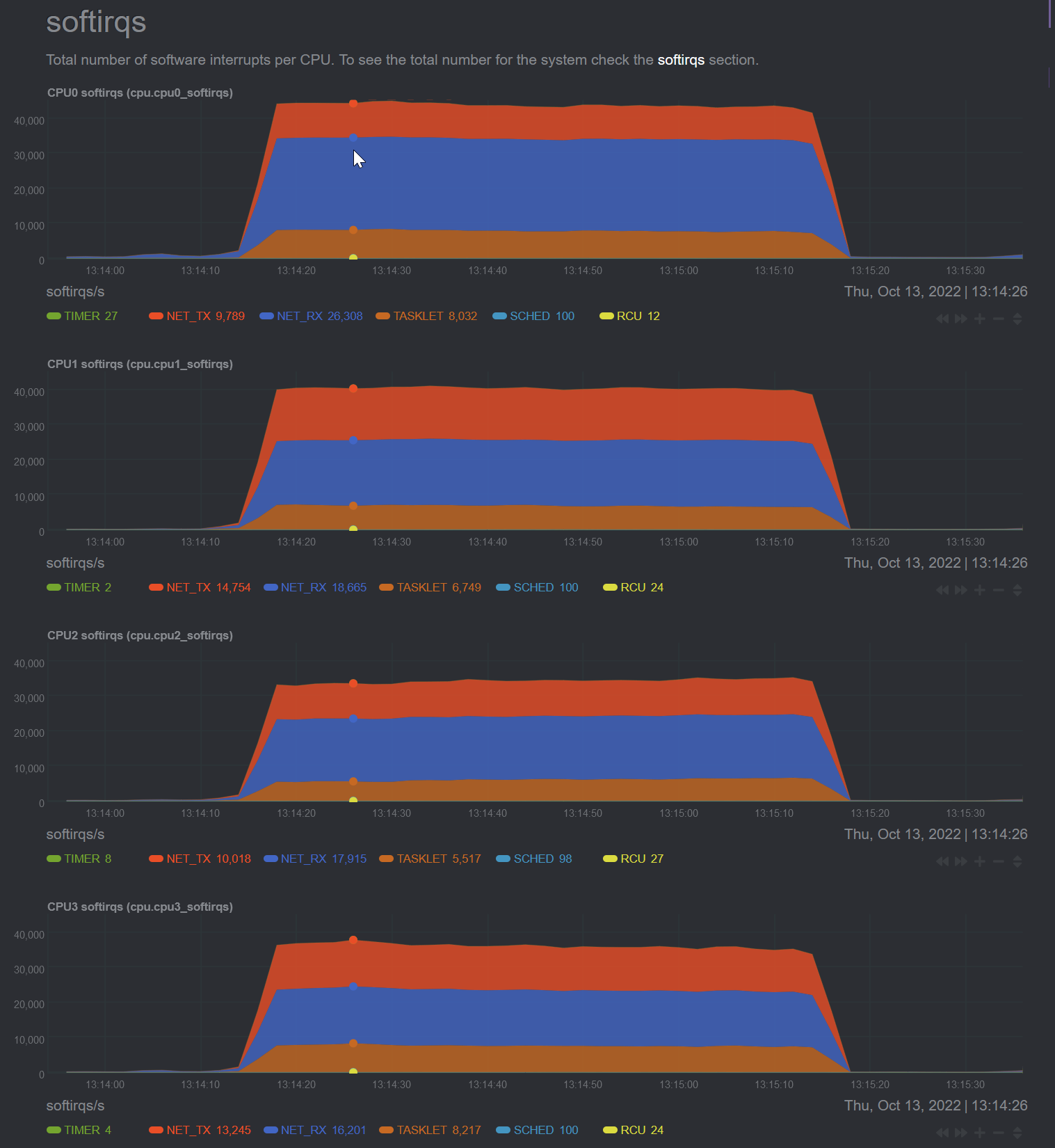
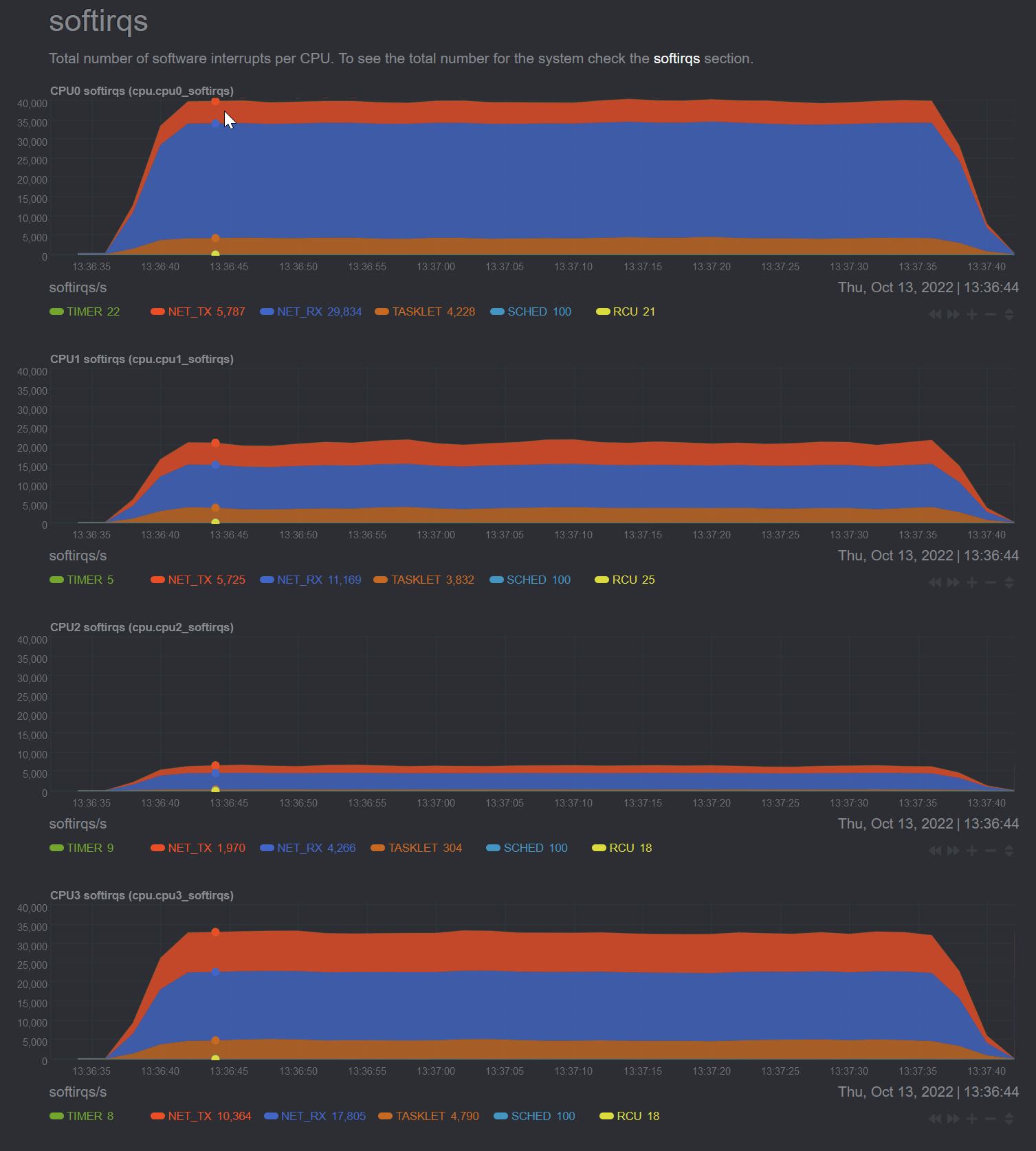
thank you for so rapidly and beautifully dashing my fantasies. That's a LOT of softirqs. What tool are you using to produce these graphs? Which flent test(s) were these?
I take it you are using htb shaper + fq_codel (simple) for the second series?
I'm always sensitive about this, it's the shaper that is 90% of the workload with fq-codel, and the BQL thing that marcin just did was to improve the latency at line rate (so I was hoping to crack 2.5gbit easily there and scale down properly to 10mbit also)
Are you running irqbalance? The performance governor?
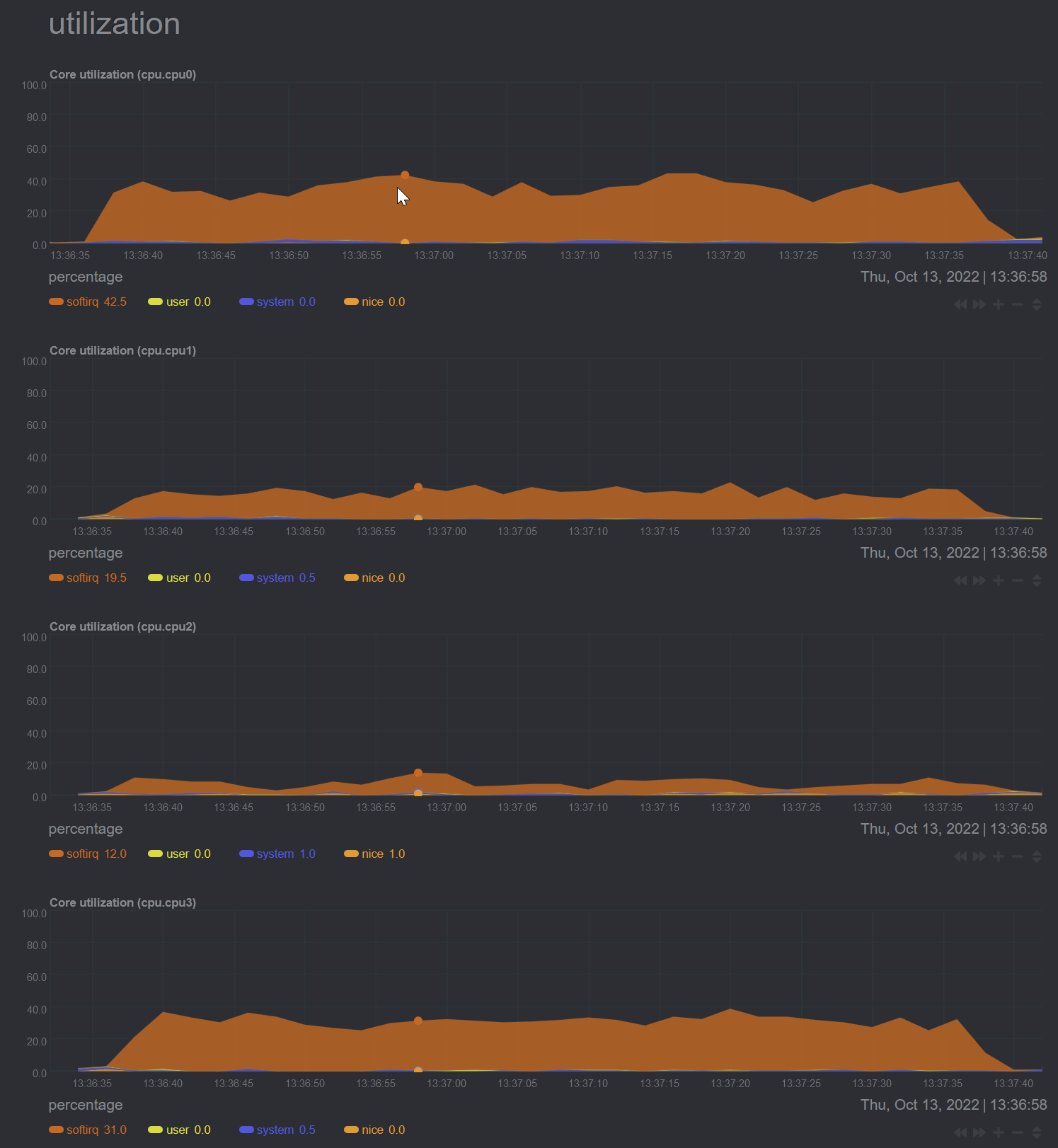
out of curiousity what does cake, unshaped, on this connection, using sch_mq so it goes on the 8 tx queues - look like (I know you want to shape to 500, but) Fastest way to try that is to
sysctl -w net.core.default_qdisc=cake
tc qdisc replace dev eth0 root cake
tc qdisc del dev eth0 root
tc -s qdisc show
I am not sure if this is a mqprio or mq device. Ideally what you would see here is sch_mq + 8 instances of cake.
It's silly to have more than one rx queue per core. The 8 tx queues either comes from an idea they are a strict priority queue (mapping CS0-CS7) usually which is one of those ideas I'm unfond of, but popular in some circles, or an artifact of that (if they are more sanely configured as equal priority queues). It makes the most sense to have one tx queue per core.