Yes, both ways are fine, I just want to make sure both continue to work as expected.... a typo is obviously a benign failure mode that might be hard to spot, but easy to fix ![]()
Lots of DOCSIS connections are about 20:1 down to up ratio or even 40:1 (200 down 5 up for example). This means a saturating download saturates upload, or at least maybe half of upload. Filtering the acks can lead to significantly more upstream bandwidth and less robo voice etc on interactive video calls or audio calls.
Yes and no, most modern TCP stacks have considerable lower ACK rates than Reno (in addition GSO and GRO will also help reduce the ACK rate)... but yes, for highly imbalanced links ACK filtering can free some reverse capacity, but I still feel that is something that should be fixed in the TCP stack, and the rest of the network should not butcher ACK streams just because it appears one can do so without too severe consequences (but here I am talking about DOCSIS ISPs that often use ACK-thinning techniques without informing/asking their users, anybody enabling it on their own router will know about the trade-off, and wil hence select the appropriate policy for their own network)....
Heh.. yeah, here in So CA USA, Cox cable was pushing a 500/10 connection as a replacement for my 300/30, that they were cancelling as a rate option. Many fought that. Currently, it's 150/10 or 500/10, with only their "gig" or $$$ biz plans with higher upload speeds. I finally accepted the 940/35, at the same price for 8-10 mo, with the option to get my old speed back. We'll see about that.
Now, I wonder if there is some kind or more filtering or thinning on their end. Just did a tc -s qdisc, on an overnight instance of SQM and assuming I'm counting right, found 55K ack drops on 6.6 million packets, for a 0.8% rate? Hadn't been paying close attention to this, but it seems like that's much lower than I remember. Cox did do some unmentioned work and "upgrades" recently, so could be new hardware in there doing something new. What it would look like if they did, and is a problem if I do as well?
I do remember a guy on another thread here though, trying ack filtering and finding 20% (!) of his traffic in acks. Slower speeds, very asymmetric link, IIRC. So, I guess it depends, as they say.
Going back to the original thread, and the reason I brought it up, it seems like my first thought of ack filtering saving some traffic and possibly help the benchmarks, isn't so likely with a fast and full symmetrical link, like was tested above.
In my gamer script I have a kind of blunt ack decimation in there. it's a hashlimit so on a per-stream basis if it gets to (if I remember correctly) 300 acks per second, it drops 50% of them at random... it does this like 4 or 5 times in a row. In general it means it's never cut below 150 acks per second, or one every 6.7 ms and never above 300/second or one every 3.3ms. I have yet to hear about any complaints associated with this. But if you're downloading at say 500Mbps with 1500 byte packets we're talking about 42k packets per second, and worst case 21000 acks per second cut down to something like 21000/2^5 = 656 acks per second. If there's 100ms delay in transport this means something like 65 acks in flight. I can't see any reason to have more than 65 acks in flight.
If a TCP scheme is more ack conscious, it won't be decimated at all (up to 300 per second). But if it's Reno then the vast majority of acks are useless garbage at modern internet conditions.
This can unclog the upload quite a bit. Especially since the cable modem is dropping them anyway.
Well, as I said it is a policy question if under control of the leaf network. But I think ISPs would do good to only ACK filter with user content. I pay my ISP to transport my packets, not to do funky things to them without telling me. I will make an exemption for geo satelitte internet, where an ISP needs to take desperate measures because normal TCPs work badly with so much delay....
The trich to ACK filtering really is to do it carefully and only omit ACKs that only differ in sequence number, and keep individual ACKs that differ in other fields like CWR. As far as I have heard not all ACK filters are that ca,reful.
About ACK rates per flow, there are schemes like dctcp that signal ECN on a packet by packet basis (com0ared to rfc3168 where the reciver will signal a received CE mark Until it is aconolwdged so for at least 1 RTT) such high frequency congestion control schemes will require more ACKs than traditional schemes. IMHO the place to fix this is the TCP stack which is in the best position to decide how many ACKs are really warranted, the network IMHO should pretend to be a honey badger and don't care 
True, but as I said the ACK rate should be "solved"/set at the TCP stack, and the solution to 1/20 access links asymmetries needs to be at ISPs (or their regulatory agency) to stop offering such plans... In theory that is something a "market" might be able to solve, but in practice that does not work because:
a) too few customers know about the technical problems (let alone that TCP needs a reverse ACK stream to make forward progress)
b) too few customers have actual choice of ISPs... (and there are generally too few ISPs anyway for a market to work well)
At which point it becomes important that the national regulatory authority (nra) steps in and remedies the situation (by say, demanding access asymmetries not to exceed say 1:8, or 1:20).
Going back a bit here.. noticed the smp affinity test, and had remembered earlier threads that touched on that for improving thruput/loading. Something I noticed that came online with 21.02.0, is a packet steering switch setting. I never got to playing with packet steering (set up via command line) but now one can flip a switch. Anyone know what flipping the switch in LUCI actually does, settings wise? IIRC, my limited reading on packet steering seemed to indicate it was complicated, with different things and ways to do stuff. Part of why I never got around to trying it.
It does seem to do beneficial things, at least on my 4 core x86 router. No speed test data, but tried A/B observations in htop during a speedtest. Eyeballing the bar graphs, the IRQload seems to be mostly distributed rather than mostly on one core. This is with my above mentioned Cake SQM settings enabled.
Interesting that the eth IRQ's move to the 3d and 4th cores. I'm not running irqbalance, or any assigning. Here's the interrupt report:
In Network - Interfaces - Global network options
Packet Steering
X Enable packet steering across all CPUs. May help or hinder network speed.
-----------------------------------------------------
OpenWrt 21.02.0, r16279-5cc0535800
-----------------------------------------------------
root@OpenWrt:~# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 25 0 0 0 IO-APIC 2-edge timer
1: 0 8 0 0 IO-APIC 1-edge i8042
4: 0 13 0 0 IO-APIC 4-edge ttyS0
8: 0 0 1 0 IO-APIC 8-fasteoi rtc0
9: 0 0 0 0 IO-APIC 9-fasteoi acpi
12: 9 0 0 0 IO-APIC 12-edge i8042
39: 0 0 0 52 IO-APIC 39-fasteoi mmc0
42: 52 0 0 0 IO-APIC 42-fasteoi mmc1
123: 0 313 0 0 PCI-MSI 32768-edge i915
124: 0 0 20 0 PCI-MSI 294912-edge ahci[0000:00:12.0]
125: 0 0 0 4541 PCI-MSI 344064-edge xhci_hcd
126: 0 0 202947216 0 PCI-MSI 1048576-edge eth0
127: 0 0 0 215391868 PCI-MSI 1572864-edge eth1
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 281896041 274042327 272326719 270077586 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 Performance monitoring interrupts
IWI: 0 0 0 0 IRQ work interrupts
RTR: 0 0 0 0 APIC ICR read retries
RES: 5404570 7678046 6333156 6304164 Rescheduling interrupts
CAL: 55811304 41852500 25565124 16702955 Function call interrupts
TLB: 9 6 12 5 TLB shootdowns
TRM: 0 0 0 0 Thermal event interrupts
THR: 1899 2327 14059 12496 Threshold APIC interrupts
DFR: 0 0 0 0 Deferred Error APIC interrupts
MCE: 0 0 0 0 Machine check exceptions
MCP: 4960 5389 17121 15558 Machine check polls
ERR: 0
MIS: 0
PIN: 0 0 0 0 Posted-interrupt notification event
NPI: 0 0 0 0 Nested posted-interrupt event
PIW: 0 0 0 0 Posted-interrupt wakeup event
A bit more food for thought, are all the prior tests in 21.02.0? I ran across someone measuring net speeds over OWT versions, on a C7, and apparently seeing a large drop in the current FW ver.
https://forum.openwrt.org/t/archer-c7-wan-lan-throughput-decreased-30-since-lede-17-01/108982
May have little to do with this thread, or maybe it's more systemic than just the C7 and all the above devices might do better?
I have a RP4 and a new 1Gbps fibre connection.
Without SQM enabled, I am getting 930Mbps download.
I enabled SQM with 740mbps download.
When I run a speed test, I'm now only getting 520Mbps download. I presume this is because the CPU is being maxed out.
How do I use the linked script to enable multicore SQM?
Thanks,
The configured speed is the shaper gross speed, while typical measurements are net throughput (also called goodput) on a higher layer. So assuming you did not configure and explicit link layer adjustments and are using TCP/IPv4 over ethernet without any options you can at best expect:
740 * ((1500-20-20)/(1500+14)) = 713.6 Mbps
520 of 713 indicates too much processing happening on one CPU, so I would try to install/enable irqbalance and or packet steering to distribute the load more evenly over the 4 CPUs.
EDIT: without LLA configured Linux defaults to 14 bytes of accounted overhead, and not the 38 bytes effective overhead of ethernet, that does change the numbers a bit, but not the conclusion that your raspberry pi seems to be doing too much on a single CPU.
1 Like
The easiest thing to try, would be enabling the packet steering, mentioned upthread. In Luci, pick Network tab, Interfaces, then the Global network options tab. If you are in 21.02.0 or later, there is now a checkbox for that. Note that it's not the same as running irqbalance (I think? Would be nice to know just what it's doing) you might try that separately and see which works better on the Pi4.
Not sure if some of the other qdisc's are multithreaded, but Cake is not. It will be on one thread, always. The benefit you get is sharing other loads over the cores, be they tasks, hardware IRQ's, or such.
You can do a cat /proc/interrupts, before and after, to see what it's doing for you. Installing htop and turning on the detailed display in settings, to see the IRQ's in the bargraphs, gives you a good dynamic idea while you're running speedtests, too.
1 Like
Many thanks to moeller0 and JonP for taking the time to reply.
I ended up using JonP's 'packet steering' solution.
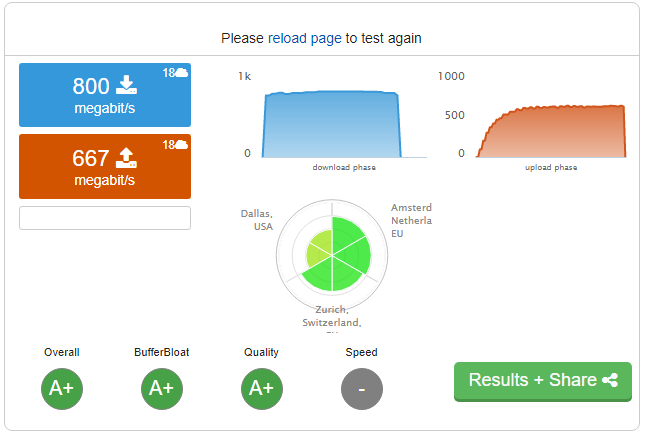
- Speedtest.net with no QoS.
- Speedtest.net with QoS.
- dslreports.com with QoS.
Maximum buffer bloat was 6ms, but was 0-1ms for the vast majority of the test.
With regards to the SQM settings, I was under the impression that the Download and Upload speeds should be set to 80% of the minimum measured speed - e.g. if my 1Gbps service was providing 1000Mbps, then I would set the speed to 800Mbps.
Have I got that wrong?
These are my current settings:
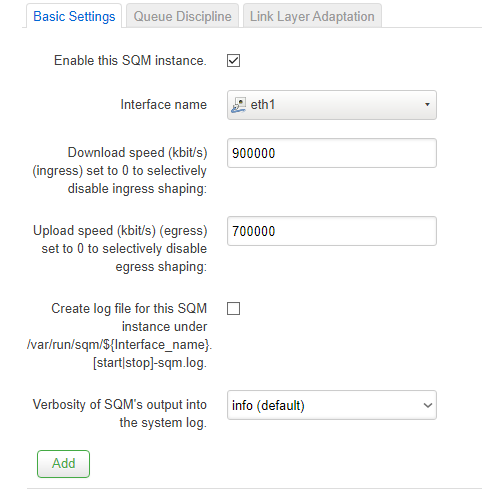
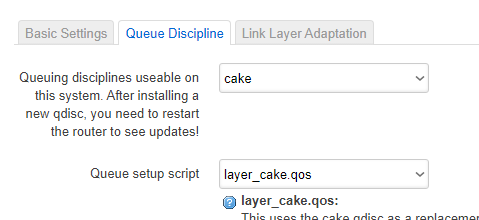
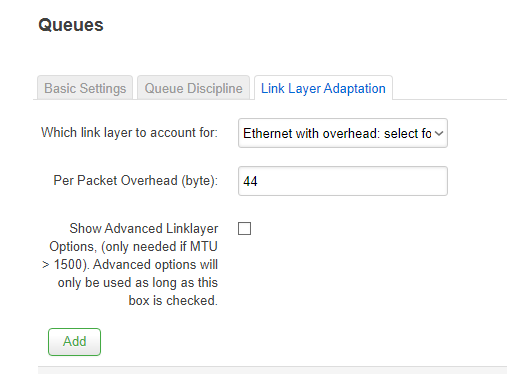
Also, I previously encountered a 'bug' when running SQM QoS on my PPPoE WAN link. The QoS wasn't being applied at startup when applied to the interface eth0.10. I had to associate it with the 'PPPoE' instance instead. Now that I am using eth1 for my WAN, will that still be an issue?
Huh, don't recognize that CPU indicator. You can see sirq, which is valuable, but greater resolution would be nice. In basic top, you get the percentages in text, in htop that and a text based bargraph, but across separate cores.
Guestimating will get you in the ballpark, testing to verify and adjusting will find out how high you can set it and still stay ahead of the bloat. DSLReports is/was good for that with their graphing, see this link for a standardized setting:
[http://www.dslreports.com/speedtest/69834829]([SQM/QOS] Recommended settings for the dslreports speedtest (bufferbloat testing))
You might have to limit/eliminate sites to get it to work, though it looks like you're doing OK from your location. Key thing that many seem to miss, is the hidden detailed graphs of the bloat when you click on the speed bars, especially with the hi res bufferbloat switch on:

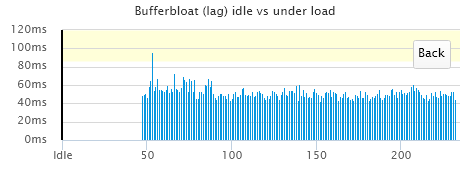
Just observe this and adjust your speeds, you can clearly see when the bloat starts in, and pick a speed just below that.
Well, your network your policy ![]() My advice currently is:
My advice currently is:
- run a few speedtests distributed over a day, and get a feel for the reliable down- and uplink speeds
- plug these goodput values as reported by the speedtest into SQM's ingress and egress rates (SQM interprets these as gross throughput, not goodput), and configure the link-layer adjustments/per-packet-overhead appropriately (your Ethernet with overhead 44 values should be okay), at that point the shaper rate will be ~5% below the true gross link rate
- test the shaper with realistic loads for your network and assess whether the values from 2) result in not more bufferbloat than you are willing to tolerate, if not reduce the shaper rates down further and re-do the bufferbloat assessment....
However, 80% of contractual rates should give you acceptable bufferbloat ![]() (at the cost of a bit sacrificed throughput).
(at the cost of a bit sacrificed throughput).
SQM uses OpenWrt's hotplug mechanism, if an interface does not cause hotplug events, SQM will never notice...
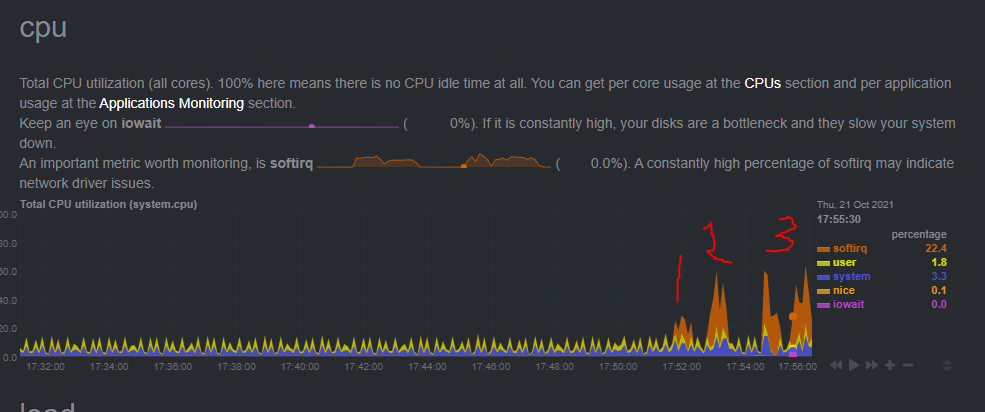
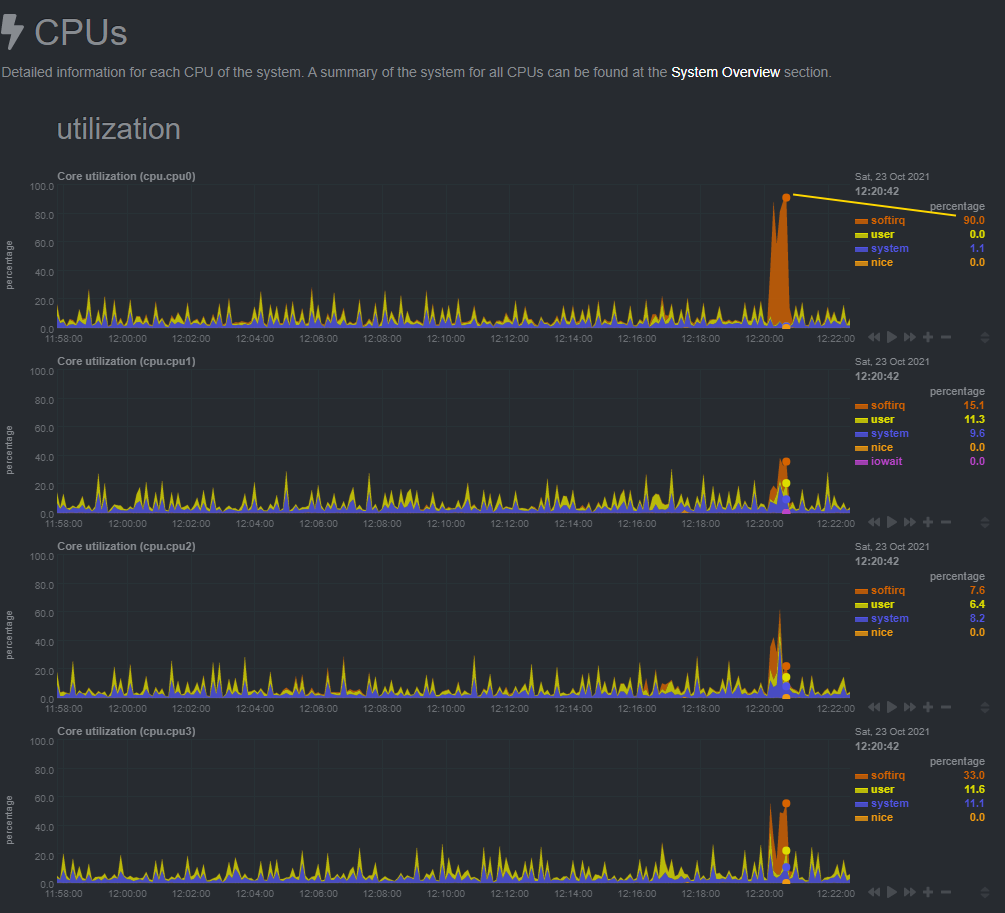
It appears that the CPU maxes out at around 800Mbps with SQM enabled.
This graph shows softirq using 100% CPU.
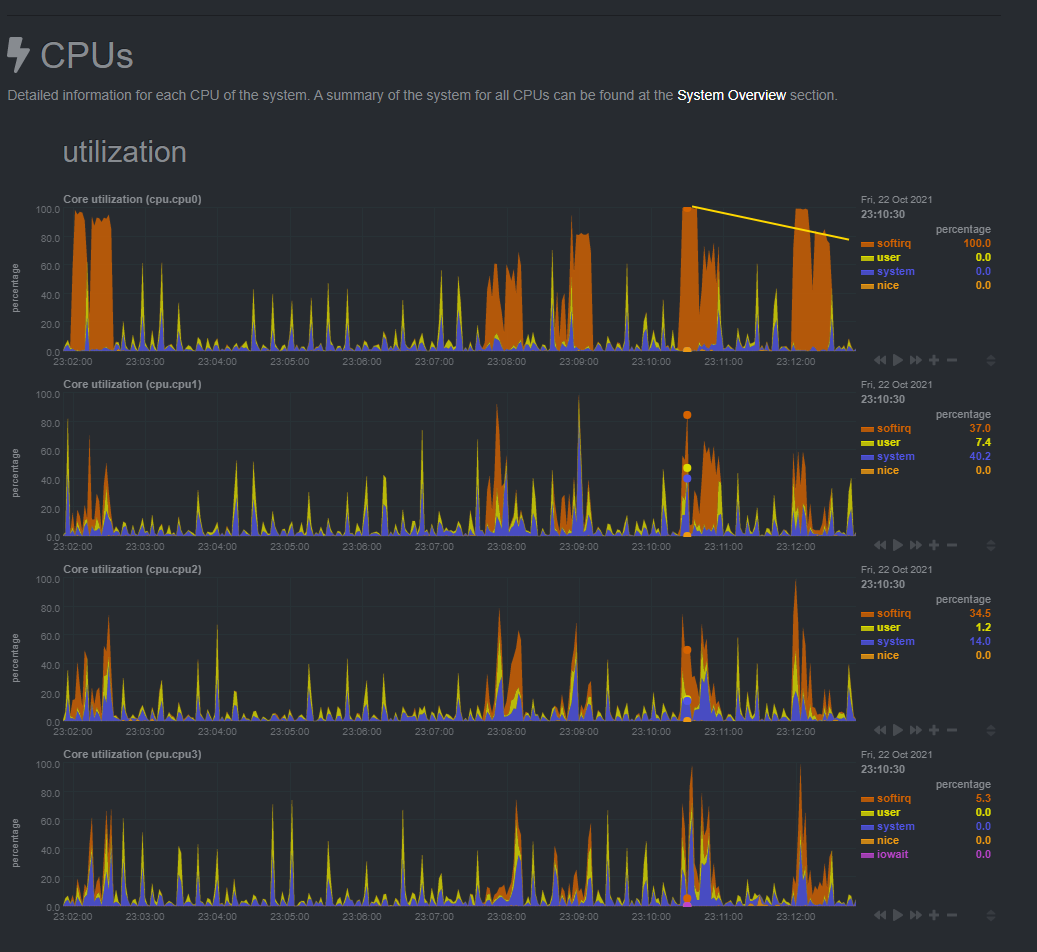
I then reduced the Download speed to 800Mbps and the CPU maxed out at 98.9%.
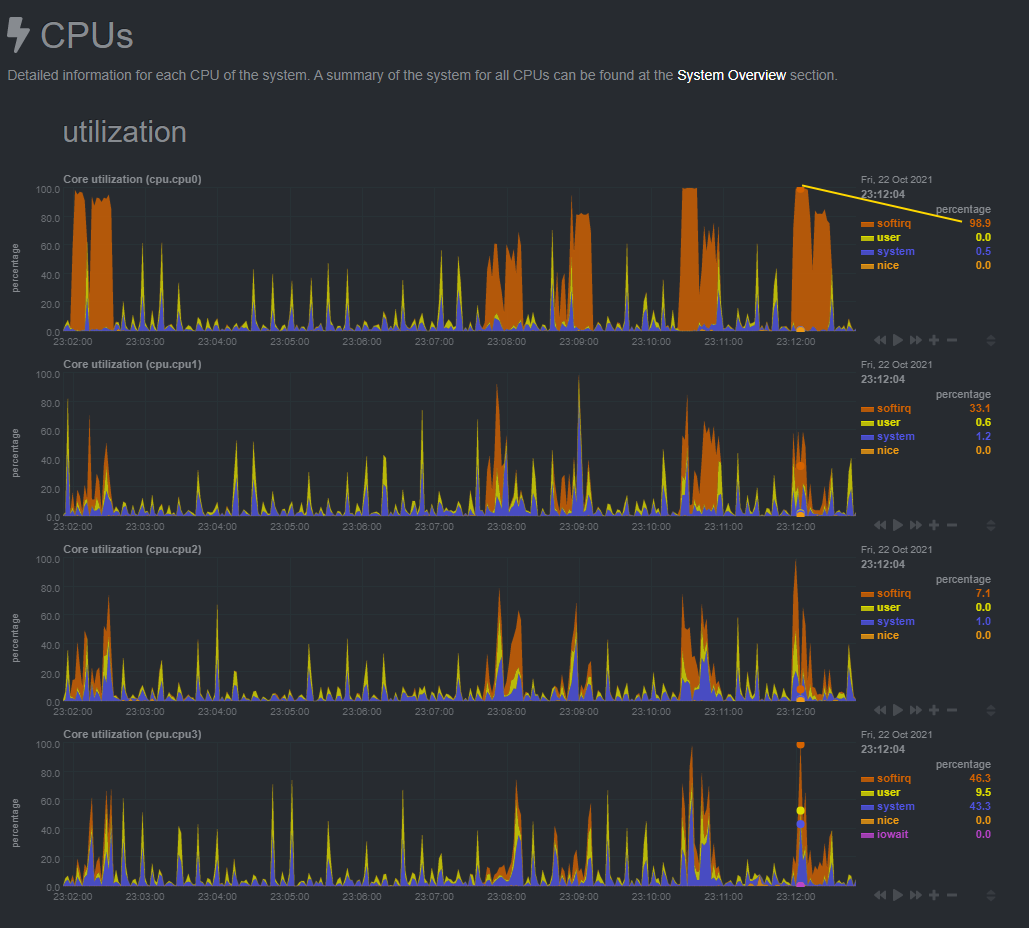
I've eased off slightly to 780Mbps Down and 640 Mbps up.
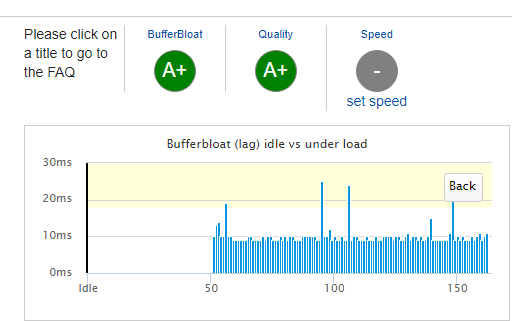

There are still a few errant pings, but I'm not sure I can do much about that.
With SQM turned off, the bufferbloat is hitting 350ms.
If SQM is using 100% of a CPU core at 800Mbps, does this mean that it could only manage simultaneous in/out totalling 800Mbps? For example, 600Mbps in and 200Mbps out, would total 800Mbps and 100% CPU?
To answer an earlier question, I am using Netdata to monitor my system. This creates a webpage that can be viewed at http://<openwrt router IP>:19999/
Turn on receive packet steering and add irqbalance... You should be able to do full speed SQM at gigabit speed.
1 Like
Thanks. I thought the two settings were mutually exclusive.
- CPU is now topping out at 90% with SQM set to 930,000 and 720,000.
Down
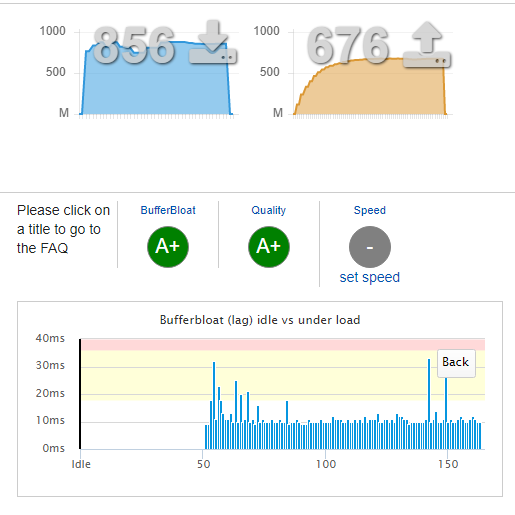
Up
What does this mean?
I previously encountered this issue:
Now that I am using eth1, do I need to do anything to have SQM enabled at startup?
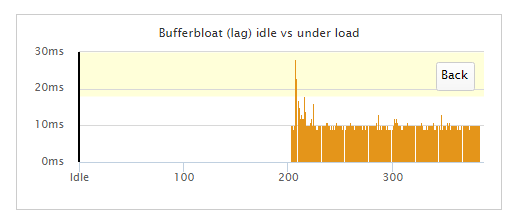
My router doesn't seem to be as stable now that I have enabled irq.
- Luci keeps freezing.
- Netdata graphs have regular gaps in the data.
Are there any known stability issues associated with that package?
Not that I know of. Try disabling it and see if it becomes more stable. Packet steering may be enough
I traced the issue to the previous PPPoE interface that I hadn't deleted. It seems to have been the route cause of all the problems.