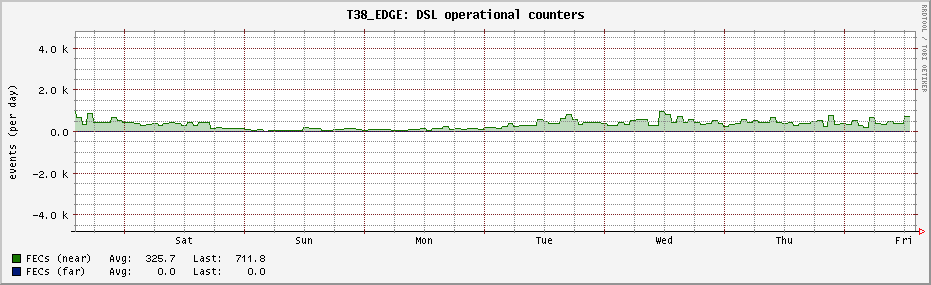
And by now they did ;), with far to little data to make robust estimates I see 3-10 minutes of no FECS... so it is working here as well.
"errors": {
"near": {
"es": 0,
"ses": 0,
"loss": 0,
"uas": 166,
"lofs": 0,
"fecs": 0,
"hec": 0,
"ibe": 0,
"crc_p": 0,
"crcp_p": 0,
"cv_p": 0,
"cvp_p": 0,
"rx_corrupted": 1050,
"rx_uncorrected_protected": 0,
"rx_retransmitted": 0,
"rx_corrected": 1050,
"tx_retransmitted": 679
},
"far": {
"es": 7,
"ses": 3,
"loss": 0,
"uas": 166,
"lofs": 0,
"fecs": 17564,
"hec": 0,
"ibe": 0,
"crc_p": 0,
"crcp_p": 0,
"cv_p": 0,
"cvp_p": 0,
"rx_corrupted": 220569,
"rx_uncorrected_protected": 150519,
"rx_retransmitted": 0,
"rx_corrected": 70050,
"tx_retransmitted": 60527
}
}
Now, I wonder which of these are actually worth reporting:
it seems that rx_corrupted = rx_uncorrected_protected + rx_corrected, but what is tx_retransmitted or rather why is tx_retransmitted not >= either rx_corrected for any of the two directions...
But looking at this gives:
/**
Structure for getting statistics counter that are related to retransmission
functionality.
*/
typedef struct
{
/**
This anomaly occurs when a received DTU with detected errors is not corrected
by the reception of a DTU, i.e. retransmission didn't correct the corrupted
DTU. The corresponding anomaly counter counts all corrupt DTUs, also idle
cells in case of ATM-TC.
\note This parameter is only valid for NEAR-END direction. */
DSL_OUT DSL_uint32_t nRxCorruptedTotal;
/**
This anomaly occurs when a received DTU, eligible for retransmission, with
detected errors is not corrected by the reception of a DTU with the same
SID, i.e. retransmission could not correct the to-be-protected corrupted DTU.
The corresponding anomaly counter counts only corrupt DTUs which belong to
the user data stream which shall be impulse noise protected by
retransmission.
\note This parameter is only valid for NEAR-END direction. */
DSL_OUT DSL_uint32_t nRxUncorrectedProtected;
/**
This anomaly occurs when a received DTU (Data Transfer Unit) is detected to
be a retransmission of a previous sent DTU.
\note This parameter is only valid for NEAR-END direction and in case of
NOT using XWAY(TM) VRX200 or XWAY(TM) VRX300. */
DSL_OUT DSL_uint32_t nRxRetransmitted;
/**
This anomaly occurs when a received DTU with detected errors is corrected by
the reception of a DTU with the same SID, i.e. a retransmission corrects the
corrupted DTU.
\note This parameter is only valid for NEAR-END direction. */
DSL_OUT DSL_uint32_t nRxCorrected;
/**
Counter of retransmitted DTU by the transmitter (rtx-tx): this is a counter
that is incremented each time a DTU has been retransmitted by the transmitter.
Multiple retransmission of the same DTU is counted as many times as it has
been retransmitted. (G.998.4 chapter 12).
\note This parameter is only valid for FAR-END direction. */
DSL_OUT DSL_uint32_t nTxRetransmitted;
} DSL_ReTxStatisticsData_t;
it might be that "This parameter is only valid for FAR-END direction." is the most relevant piece of information here...
Then again ITU G.994.4 chapter 12 says:
" 12 DTU counters
For trouble-shooting and testing of the retransmission functionality, three DTU counters are defined to monitor the retransmissions:
- – counter of uncorrected DTU (rtx-uc): this is a counter that is incremented each time a DTU is detected in error and has not been corrected by one or more retransmissions within the delay_max constraint;
- – counter of corrected DTU (rtx-c): this is a counter that is incremented each time a DTU has been detected in error and has been successfully corrected by a retransmission;
- – counter of retransmitted DTU by the transmitter (rtx-tx): this is a counter that is incremented each time a DTU has been retransmitted by the transmitter. Multiple retransmission of the same DTU is counted as many times as it has been retransmitted.Those counters are 32-bit values with wrap-around and shall be maintained by the xTU. They shall be available upon request over the eoc. The counters shall be reset at power-on. The counters shall not be reset upon a link state transition and shall not be reset when read."
My gut-feeling is that they might start out being non-zero somehow and that initial offset might make is hard to see the relevant changes...